Introducing Covariate Labeling: Outperforming Zero-Shots with Raw Encoders
Michelangiolo Mazzeschi • 2024-12-17
Raw-encoders cannot be used classification, this article shows how to make this possible
The zero-shots models
***To understand this article, knowledge of embeddings and zero-shots systems is required. The implementation of this algorithm has been released on GitHub and is fully open-source. I am open to criticism and welcome any feedback.
In this article, I am going to introduce a novel approach to labeling called covariate labeling or covariate tagging. At the moment, the two most common approaches to labeling using machine learning are:
- Zero-shots
- LLM tagging
Despite LLMs being exceptional at labeling samples (an advantage given by their reasoning abilities), their computational demands are in the order of magnitude greater than the first option.
Zero-shots models, on the other hand, are much more lightweight (they can pretty much run on a single computer), and their performance is suboptimal.
In addition, neither options allow for a large number of choices. If, for example, we had to choose between a list of over 50 tags, we would need to start employing semantic approximation methods such as clustering to cap the number of possible tags. Even the best zero-shots models might need several minutes of processing to run a large number of tags.
In conclusion, the current technology offers no viable option to perform zero-shot labeling at scale.
What about raw encoders?
So far, we have not mentioned a third labeling method: raw encoders. This approach consists in using cosine similarity to determine which ones are the top labels among the list. This method is considered so bad that is not even attempted. Today, we are going to turn the tides and put it back among the top-tier list of labeling tools.

Why are raw encoders so bad?
There are two limitations that cripple this approach:
- Cosine similarity is not a reliable classification metrics It is very common for cosine similarity to mistake a label for another, and give results that make absolutely no sense. This is the main reason why it has been abandoned from any classification task.
- We do not know how to stop knn
There is no optimal number of neighbors (unless you employ advanced techniques like adaptive-knn, which has never been experimented on this approach, to my knowledge). No matter how many labels we throw to the model, they will just be given a score, and there is no proper way of selecting the top k tags (being optimal k unknown).
Covariate Tagging
This new approach is built on top of covariate encoding and it is based on the assumption that we can semantically map a query vector with an encoded set of labels. We can then filter out the top candidates by finding out the inflection points among the scores. This algorithm can even rely on a huge number of tags (even 1000), extending the limitations of the zero-shots models (which can barely handle 20).
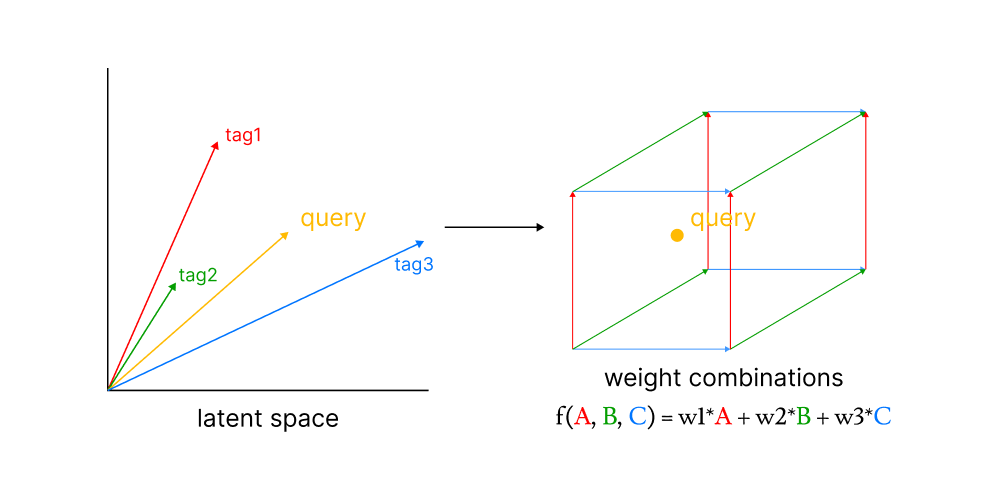
The theory behind this algorithm is that by taking into account the span of the set of zero-shots vectors (an embedded space that is made of all their possible combinations, you can picture it as a hypercube), we can map the optimal weight combination of zero-shots using non-negative last squares. This combination of weights lists the set of labels that can be used to tag the base query.
Our goal is to propose a solution that can greatly outperform zero-shots, and despite not being a match with the reasoning abilities of LLMs, it can still outperform them in terms of input limit (LLMs can maybe process 50 tags, covariate tagging can handle thousands without breaking a sweat).
Preparation
To create our zero-shot model, we need proper samples and a number of tags used for classification. One dataset that I have been using in many tagging situations is the Steam game dataset, which contains over 40.000 game descriptions and only 446 tags (which is enough to demonstrate the capabilities of covariate tagging, but not excessive to require further processing, as it would be a list of 10.000 tags).
Our goal is to improvise a classifier capable of converting any textual game description into a set of labels chosen from the list of 446 tags. Note that this approach uses a pre-trained raw encoder, and does not require any training on our end.
# random sample of our list of zero-shots (out of 446)
['Dragons',
'Tactical RPG',
'Nudity',
'Villain Protagonist',
'Colony Sim',
'Tutorial',
'Lemmings',
'Movie',
'Dungeon Crawler',
'Sci-fi',
'Tactical',
'Asymmetric VR',
...
]In our experiment, we will try to find the labels for the following game description:
Death is lonely. He has zero friends on his FaceTome account and no one to hang out with. So, in order to feel better he
begins “Project Deadlings”. Death buys a factory where he can build his laboratory and begin training a massive army of
zombie minions. As the army of Deadlings grows, the mazes of the laboratory become deadlier, loaded with puzzles and
death-defying traps. Different Deadlings have their own unique abilities: Bonesack is agile - he can run and jump, Creep
can climb on walls and ceilings, Lazybrain treads slowly but carefully and Stencher... well Stencher has gastric
problems so he can use his powerful gas clouds to fly. You will have to combine all of these abilities to find your way
in Death's Maze. Can you help Death to kill his boredom? Will you be able to navigate all 60+ levels available in
Deadlings? Will you complete Project Deadlings, and successfully train all of your zombie minions? Arcade side-scroller
with strategy elements! Four different types of zombie minions with unique abilities! 70 levels of pure zombie gore fun!
Additional game mode - Nightmare - only for the hardcore gamers! What's new in the Rotten Edition? 10 brand new bonus
levels 15 new levels in Nightmare Mode Steam achievements and leaderboards Full controller support Nightmare mode
unlocked from the beginning Steam Trading Cards and Badges HD graphics1. Generate zero-shots hypercube
Our first step will be to create a space built on the base of the zero-shot labels. We are going to use a numpy hstack function. The coordinates of this space represent the weights of the zero-shot labels that have been used to build it.
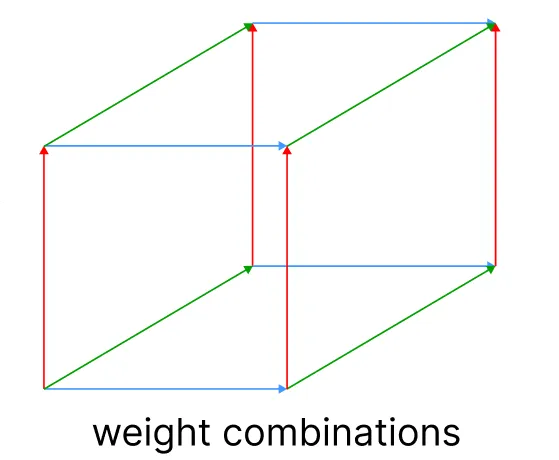
2. Map the query with the hypercube
Our second step will be to align the coordinates of our query vector in the hypercube.
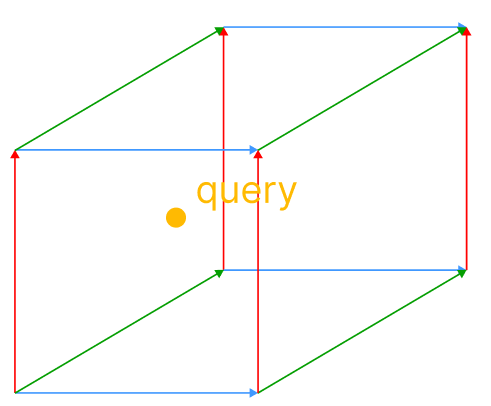
The vector corresponds to a weight combination, the only step left it to figure it out..
3. Inference weight combination
To perform this last step we are going to use non-negative least squares. The choice behind this algorithm is straightforward: if we were to allow for negative value to exist, this would allow the model to choose non-related tags (ex. in the context of our query we could even have “basketball”, because there could be an exact opposite vector able to compensate for its negative value.
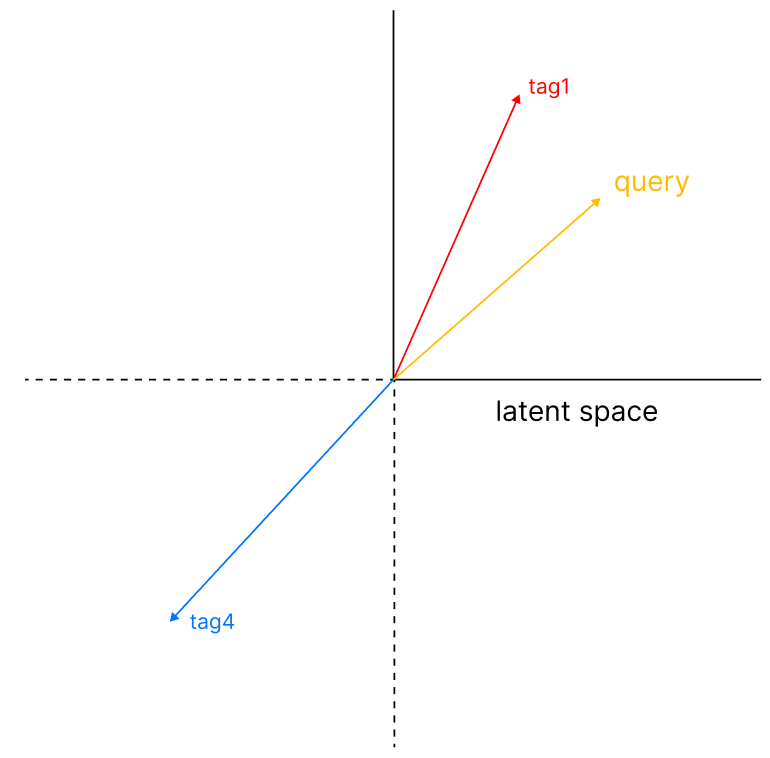
But, by limiting our choice to only positive vectors, the labels are much more coherent.
4. Filter scores using inflection points
We can show the score of all the weights that have been inferenced from our hypercube. The red lines below indicate the strongest shift in score (inflection points):
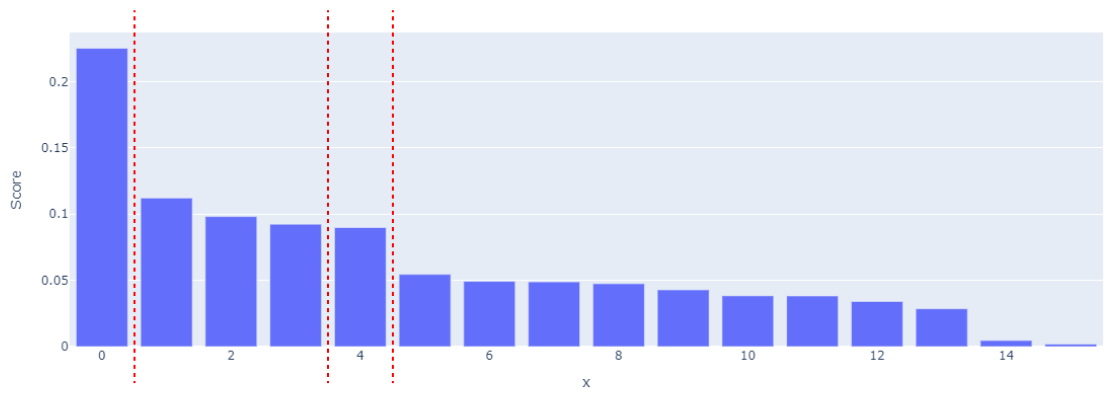
We can use the inflection points as thresholds.
The algorithm has successfully selected the top-k labels from our input text, and it has run in just 0.05 second! Something we have never seen before (by simply using a raw encoder!).
# filtering up to the 2nd inflectio point
[
'Silent Protagonist',
'Tutorial',
'Dungeon Crawler',
'Level Editor',
'Open World Survival Craft',
'Perma Death',
'Zombies'
]If we compare the tags obtained through our novel methods with the ones sorted by knn, we realize the big performance difference (the results get more impressive when there are group of tags that are similar to each other sorted at the top, which is the biggest flaw or raw encoders: in such cases only a tag per group gets selected, as it should be).
[
'Zombies'
'Dungeon Crawler',
'Survival Horror',
'Mystery Dungeon',
'Open World Survival Craft',
'Survival',
'Perma Death',
'Puzzle-Platformer',
'Solitaire',
'Silent Protagonist',
'Roguelike Deckbuilder',
'Dungeons & Dragons',
'Action-Adventure',
'Life Sim',
'Games Workshop',
'Level Editor',
'2D Platformer',
'Minigames',
'Sandbox',
'Character Action Game'
]With regular knn, similarity scores are never consistent, making it impossible to choose a threshold.
Evaluation
As beautiful (and fast) as it is, let us not forget that we are relying on a raw encoder. This means that some terms will still be classified as ambiguous, while the room for error is still marginally high.
Let us compare the same labeling assigned using the best open-source zero-shots models:
bart-large-mnli
The results are not actually bad, the major issue is that the entire process took 7 minutes! (which makes scalability quite challenging).
['Side Scroller',
'Arcade',
'Gaming',
'Strategy',
'Difficult',
'Addictive',
'Zombies',
'Controller',
'Well-Written',
'Game Development',
'Dark',
'Immersive',
'Dystopian',
'Competitive',
'Stylized',
'Rogue-like',
...zero-shot-implicit-bi-encoder
This zero-shot model is one of the latest open-sourced models, and the processing of all 446 tags only took 6 seconds (substantial improvement compared with traditional systems).
[(0.654, 'Relaxing'),
(0.564, 'Story Rich'),
(0.548, 'Dungeons & Dragons'),
(0.547, 'Adventure'),
(0.537, 'Immersive Sim'),
(0.534, 'Family Friendly'),
(0.532, 'RPGMaker'),
(0.524, 'Party'),
(0.521, 'Magic'),
(0.512, 'Life Sim'),
(0.503, 'Web Publishing'),
(0.496, 'Party-Based RPG'),
(0.496, 'Futuristic'),
(0.495, 'Survival'),
(0.494, 'Roguevania')
...However, we can agree that the results are suboptimal (it seems like it is overly generalizing the text).
To be really satisfied with our classification we should be using LLMs, but, as explained, those models belong to a completely different generation.
Conclusion
I might be bold enough to call this a breakthrough. This should open a new door for zero-shots applications, as it shows that there is no need for training ad hoc neural networks to perform any proper labeling.
In Conclusion, our approach:
- Breaks all records for zero-shot input size
- Outperforms the accuracy of zero-shots, but not LLMs
- Is, at least, 1000x faster than any other known method
See More Posts
Cardy
Copyright © 2021 Govest, Inc. All rights reserved.